Notes following this MIT course and is based on the xv6 toy operating system.
- Operating System Interfaces
- Processes and Memory
- Operating System Organization
- Page Tables
- Traps and System Calls
- Interrupts ad Device Drivers
- Locking
- Scheduling
- File System
Operating System Interfaces
- Operating systems serve a number of purposes
- Abstracts away lower level hardware, so that programs don’t have to care about what disk you are writing to
- Allows multiple programs to run “at the same time”
- Provide well defined interface for programs to interact with each other
- For the interface, we want a simple interface that is easy to implement, but allows high sophisticated operations to happen
- UNIX philosophy of composing many simple programs together helps keep this problem trackable
- Can divide operating system into kernel space and user space
- kernel space is the program which provides services to other programs. It’s given hardware level privileges which user programs don’t have access to
- Each running program under the kernel’s manager (called a process) gets it’s own memory which houses the instructions (ie. the CPU assembly instructions), the data (variables created when running the program) and the stack (organizes program procedure calls)
- if process needs a kernel service, it invokes a system call, which briefly transfers ownership to the kernel, which executes the syscall, and then returns ownership to the user program
- Called user space and kernel space
- Typically, people use a shell to allow user input. The shell resides in user space, so you have flexibility in what shell you run
Processes and Memory
- For each running process, there is some user-space memory (instructions, data, stack) and kernel-space memory (which the user’s can’t access)
- One of the kernel-space things is the PID (process identifier)
- Xv6 has it’s own custom syscalls, which are somewhat stripped down versions of the UNIX ones
- Unless otherwise stated, all of these calls return 0 for no error and -1 if there’s an error
| Call Sig | Desc |
|---|---|
| int fork() | Create a process, return child’s PID. Makes an exact copy of user-space. returns in both parent and child process. Returns child’s PID in parent process, and 0 in child process |
| int exit(int status) | Terminate the current process; Releases all held resources. Exit status reported to wait(). No return. |
| int wait(int *status) | Wait for a child to exit; exit status in *status (out parameter); returns child PID. If caller has no children, immediately returns -1. If parent don’t care about child exit status, pass 0 address (ie. (int *) 0) to wait |
| int kill(int pid) | Terminate process PID. Returns 0, or -1 for error. |
| int getpid() | Return the current process’s PID. |
| int sleep(int n) | Pause for n clock ticks. |
| int exec(char *file, char *argv[]) | Load a file and execute it with arguments; only returns if error. This replaces the current process’s memory with that of the file. For Xv6, the ELF format is used. |
| char *sbrk(int n) | Grow process’s memory by n bytes. Returns start of new memory. |
| int open(char *file, int flags) | Open a file; flags indicate read/write; returns an fd (file descriptor). |
| int write(int fd, char *buf, int n) | Write n bytes from buf to file descriptor fd; returns n. |
| int read(int fd, char *buf, int n) | Read n bytes into buf; returns number read; or 0 if end of file. |
| int close(int fd) | Release open file fd. |
| int dup(int fd) | Return a new file descriptor referring to the same file as fd. |
| int pipe(int p[]) | Create a pipe, put read/write file descriptors in p[0] and p[1]. |
| int chdir(char *dir) | Change the current directory. |
| int mkdir(char *dir) | Create a new directory. |
| int mknod(char *file, int, int) | Create a device file. |
| int fstat(int fd, struct stat *st) | Place info about an open file into *st. |
| int stat(char *file, struct stat *st) | Place info about a named file into *st. |
| int link(char *file1, char *file2) | Create another name (file2) for the file file1. |
| int unlink(char *file) | Remove a file. |
Forking
- As a small case study, look at the following C snippet
int pid = fork();
if(pid > 0){
printf("parent: child=%d\n", pid);
pid = wait((int *) 0);
printf("child %d is done\n", pid);
} else if(pid == 0){
printf("child: exiting\n");
exit(0);
} else {
printf("fork error\n");
}
- After the fork(), the pid let’s you determine what the parent and the child do
- NOTE: While after forking, the memory and register content of both processes is the same, they located in different locations which can evolve independently from each other
- Don’t expect the output to be the same. Whichever process gets to printf first will output first (parent and child output could also be interleaved)
Exec
- Another case study of exec
char *argv[3];
argv[0] = "echo";
argv[1] = "hello";
argv[2] = 0;
exec("/bin/echo", argv);
printf("exec error\n");
- If echo is functioning properly, then the last printf will never get executed
- Argv[0] is typically reserved for the program name
Operating System Organization
- An operating system has three requirements
- multiplexing: multiple processes should be able to access the same hardware resources (time-sharing)
- isolation: each process should not be subject to the bugs of another process (ie. if one process goes under, the others keep running)
- interaction: processes should be able to interact with each other (eg. like UNIX pipes)
- xv86 runs on a multi-core RISC-V processor, and is written in “LP64 C” ,which means longs and pointers are 64 bits, but integers are 32 bits.
Abstracting Physical Resources
- In theory, you don’t need an operating system. Just provide a library to interact with the hardware resources, then allow programs to link against this library
- real-time systems and embedded devices do this for speed reason
- The problem with this approach is that it requires each program to trust each other (ie. yield control of the CPU time to achieve multiplexing, called coperative time-sharing) and not have any bugs. Both of these are ludicrously naive
- UNIX uses a file system to abstract the hardware so that programs don’t have to fully trust each other
- This hardware abstraction also allows transparent switching between hardware CPUs (save registers when you switch, load them back in when you come back)
CPU Modes
- Three modes of CPU
- machine mode: instructions have full privilege
- privilege mode: only the kernel can run in this mode. If a user program tries to execute one of these instructions, it’s gets terminated by the kernel
- user mode: most restricted mode of cpu
- Need to use a special function to transition to privilege mode
- Operating systems need to make a choice about what mode it will run in
- UNIX makes the choice of putting everything in privilege mode (monolithic kernel)
- Another choice is to have most of the code in user space though (called a microkernel), since if you mess up in kernel mode, everything crashes
Processes
- A process is stored in a struct at kernel/proc.h inn xv86. This info lets the process act like it has it’s own CPU, and act like it has it’s own memory
- Each process has a thread of control, which holds the state needed to execute the process (p->thread)
- Each process has two stacks: a user space stack(p->stack), and a kernel space stack (p->kstack)
- in RISC-V, ecall is used to enter kernel space, and sret is used to return to user space
- p->state indicates wheather the process is allocaated, ready to run, currently running, waiting for I/O, or exiting
- p->pagetable holds the process table info, formatted for RISC-V
- The pagetable is responsible for translating virtual addresses (ie. the addreses a CPU instruction manipulates) to a physical address (an address that the CPU chip sends to main memory)
xv6 startup
- CPU first reads and execute the bootloader from ROM, which loads the rest of the kernel
- The RISC-V starts with paging hardware disabled
- The bootloader puts the kernel at 0x80000000 (place here b/c I/O devices are in the lower range), and the starts executing at _entry
- at _entry, there is a start function which does things only machine mode:
- acts like it returns from supervisor mode (even though you are running in machine mode)
- sets the return address to that of main
- disables the virtual address space
- delegates all interrupts and exceptions to supervisor mode
- and then programs the clock chip to generate interrupts
- in the main function
- it creates the first user process
- the first syscall called is exec, replaces the current process with the shell
- the args to exec get put in a0 and a1, and puts the syscall number in a7
- syscall number matches the entries in the syscalls array, a table of function pointers
- syscall retrieves the syscall number from a7
- The first syscall is SYS_exec
- once sys_exec returns, it’s return value is put in p->trapframe->a0
- This causes the original userspace call to return that value
Security
- The kernel assumes that user code is malicious (ie. it will try it’s best to crash the system)
- The kernel space code is assumed to be safe\
Page Tables
- Xv6 uses page tables to implement isolation. Maps virtual addresses (address that RISC-V instruction manipulates) to physical addresses (address that CPU sends to main memory)
- the top page of the address houses the trampoline page and the trapframe page, each of 4096 bytes
- the trampoline page contains the code to transition in and out of the kernel
- the trapframe page houses the process’s user registers
- the top page of the address houses the trampoline page and the trapframe page, each of 4096 bytes
- To elaborate on the mapping:
- only the bottom 39 bits out of the 64 bits are used for virtual address
- in RISC-V, there are $2^{27}$ page table entries (PTE). each PTE contains a 44-bit physical page number (PPN)
- These flags are used to state now that page can be used
- PTE_V indicates wheather a PTE exists
- PTE_R indicates if you can read the page
- PTE_W controls if you can write to a page
- PTE_U controls if user mode instructions can access the page
- These flags are used to state now that page can be used
- The top 27 bits of the 39 bits are used to index into the page table to find a PTE
- You can then construct a 56-bit physical address whose top 44 bits come from the PPN in the PTE, and whose bottom 12 bits are from the virtual address
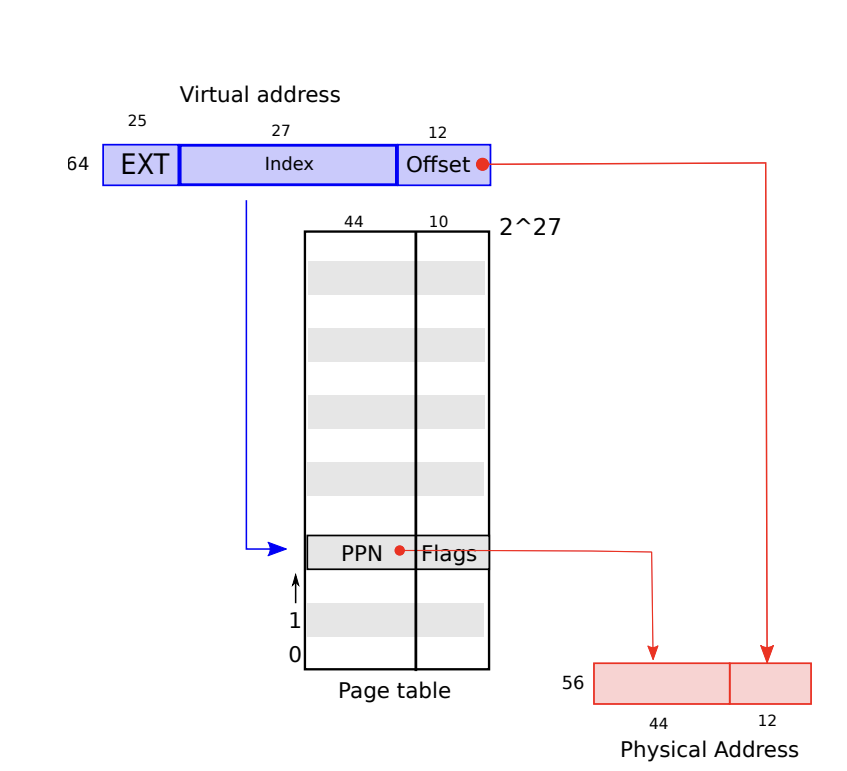
- RISC-V uses a hierarchy of pagetables, since that uses less data (for example, three sections of 9 bits are used to index 3 levels of page tables)
Kernel Address space
- Each process gets one page table. The kernel gets it’s own page table to describe it’s address space
- The kernel uses direct mapping (ie. virtual addresses are equal to physical addresses). The cases where direct mapping isn’t used by the kernel are
- The trampoline page: it’s mapped to the top of the address space. The user page tables also have this same mapping. This allows you to easily transfers registers between layers
- The kernel stack pages: each process gets it’s own kernel stack, along with an unmapped guard page whose PTE is invalid. This helps guard against stack overflows
Xv6 Implementation
- The central datastructure is pagetable_t, which is a pointer to a RISC-V root page-table page
- This can either be a kernel page table, or a preprocess page table
- Early on in booting, the kernel’s page table gets constructed prior to paging being enabled
- The root page-table pge gets allocated, then gets populated with the translations the kernel needs, then the kernel stack for each process gets allocated (leaving space for the guard pages) and the appropriate flags are set
Physical Memory Allocation
- The kernel is responsible for allocating and freeing physical memory at runtime for page tables, user memory, kernel stacks, and pipe buffers
- xv6 uses physical memory from the end of ther kernel to PHYSTOP for run-time allocation
- Allocation consists of removing a page from the linked list, while freeing is adding a page to the list
Xv6 Physical Memory Implementation
- the main data structure of the allocator is a free list of physical memory pages
- each entry in the list is a struct run. The struct stores each run structure in the free page itself, since nothing else is stored there
- The struct has a spin lock on it, which means you need to acquire and release the lock (don’t worry about this for now…)
- The free list is initialized to hold every page between the end of the kernel and and PHYSTOP
- Normal operating systems can figure out how much to allocate via some hardware configurations. Xv6 just assumes 128 Mb of RAM
- a PTE can only refer to a physical address that is aligned to the 4096-byte boundary, so PGROUNDUP macro does this alignment
- The allocator treats addresses in two different ways
- As integers in order to perform arithmetic
- As pointers to read and write memory
- The aforementioned reasons is why there are so many C type casts
- Xv6 sets all freed memory to 1 via kfree (to try and catch dangling references)
- kfree repends the page to the free list (so the list grows head first)
Process Address Space
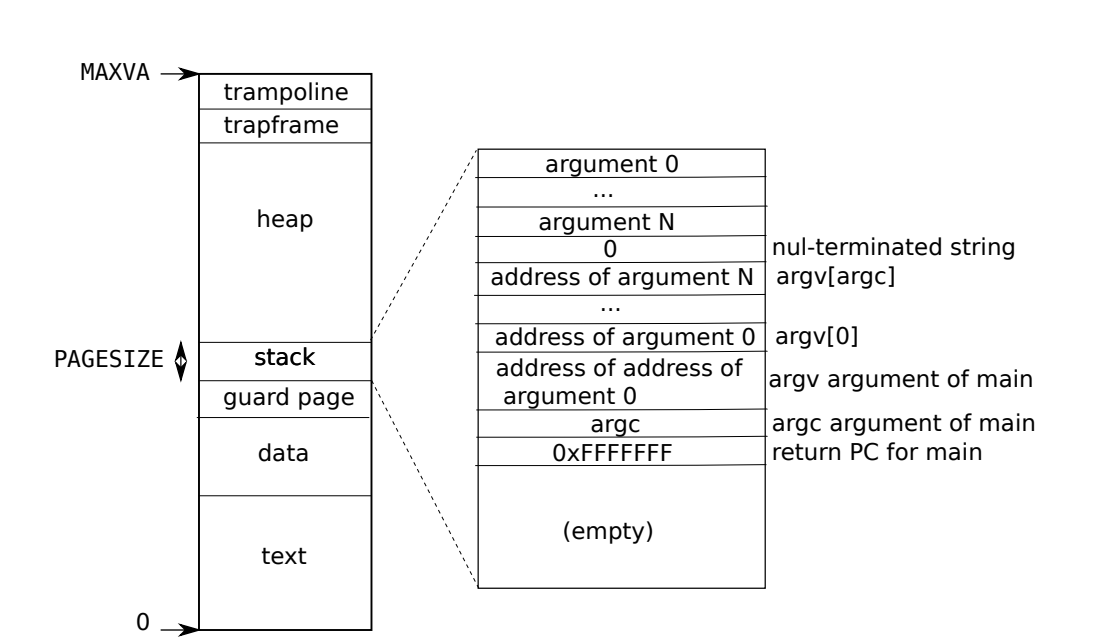
- Each process gets it’s own page table. When processes get switched, it also changes page tables
- When a process asks for more memory, xv6 uses kalloc to allocate physical pages, and then populates the page table with the correct PTEs. The OS also sets the correct permissions on the page
- This schema has some nice advantages
- Different process page tables translate user addresses to different pages of physical memory. This allows each process to have a private user memory
- Each process sees its memroy as having contiguous virtual addresses starting at 0, which physical memory is non-contiguous
- The kernel maps a page with trampoline code at the top of user address space, which means that a single page of physical memory shows up in add address spaces (hence, allows you to share between processes)
- Referring to above figure, we note that the user stack is a single page, followed by a guard page, which acts as a way to detect a stack overflow. Xv6 just panics, but a real OS would try to allocate more memory for the user stack
Sbrk (Xv6)
- Sbrk is used by a process to grow or shrink memory. Depending on the sign of allocation, sbrk either allocates or deallocates a page at a time as needed (so if you allocate 1 byte, 1 whole page will be allocated)
Exec (Xv6)
- Exec creates the user part of an address space
- If does this by reading a file stored in the file system in the form of an ELF file
- It first reads the first 4 bytes to check of the magic number matches ‘0x7F’, ‘E’, ‘L’, ‘F’. If it matches, it assumes that the file is formatted correctly
- A new empty page table is allocated, then each ELF segment is allocated with uvmalloc then loaded with loadseg
- walkaddr is used to find the physical addresses of the allocated memory
- exec then allocates and initializes one page for the user stack, along with a guard page to protect against overflow and too many arguments
- If any program segment is invalid, the program image is freed, and exec returns -1.
- Exec is risky, since addresses in the ELF file can refer to the kernel. So user programs can in theory gain kernel privileges
Real World Paging
- real world operating systems deviate from Xv6 drastically
- Real OS’s don’t crash if a user stack overflows. They actually try to save a page=fault exception
- Xv6 assumes that physical RAM is always at 0x8000000. The real world can’t make this assumption. Real OS’s need to be able to map arbitrary hardware physical memory layouts into predictable kernel virtual address layouts
- On machines with large amounts of memory, you might want to use “super pages” (ie. make pages 4 Mb instead of 4kB) to avoid excess page-table manipulation
- the lack of malloc prevents the kernel from using data structures with require dynamic allocation
- Real kernels would allow allocation of variable size blocks instead of a hard-coded 4096 bytes
Traps and System Calls
- “Traps” refer to any event which causes the CPU to set aside ordinary execution of instructions
- Could be a system call
- Could be an exception (ie. an instruction has done something illegal)
- Could be a device interrupt: when a device signals that it needs attention
- Traps often should be transparent to other processes (ie. other code shouldn’t know that they happened)
- The overall structure of trap handling is
- a trap forces control to transfer to the kernel
- the kernel saves registers and other state so that execution can be resumed later
- the kernel executes the appropriate handler code
- the original code resumes where it left off
- “Handler” refers to code which that processes a trap
- The first handler instructions written in assembly are called a “vector”
RISC-V traps
- RISC-V CPUs have a set of control registers that
- the kernel writes to to tell the CPU how to handle traps
- the kernel can read from to find out about how a trap occurred
- The most important registers are:
stvec: the address of it’s trap handler. RISC-V jumps to this address to handle the trapsepc: When a trap occurs, RISC-V save the program counter here- the
sretinstruction copiessepctopc. The kernel can write tosepcto change wheresretgoes
- the
scause: RISC-V puts a number here that describes the reason for the trapsscratch: the trap handler code uses this to help overwrite user registers before saving them (ie. a scratch pad)sstatus: the SIE bit insstatuscontrols weather device interrupts are enabled. If the kernel clears SIE, RISC-V will defer device interrupts until the kernel sets SIE. The SPP bit indicates whether a trap came from user mode or supervisor mode and controls to what mode rset returns
- You can’t read or write these registers in user mode. A similar set of registers exist for traps handled in machine mode (xV86 only uses these for timer interrupts)
- RISC-V does the following sequence:
- if the trap is a device interrupt,
ssstatusSIE is cleared. Don’t do any of the following - Disable interrupts by clearing the SIE bit in
sstatus - Copy the pc to sepc
- Save the current mode in the SPP bit in status
- set scause to reflect the trap’s cause
- set the mode to supervisor
- copy
stvecto thepc - Start executing in supervisor mode
- if the trap is a device interrupt,
- In theory, you could skip some of these steps. In practice, you want to maintain process isolation (ie. prevent user code from running kernel level instructions)
- Note that the CPU doesn’t do the following operations. It’s the kernel’s job to do these tasks. The CPU does this to allow greater flexibility for the OS (for instance, some OS’s omit the page table switch in some situations for performance reasons)
- Doesn’t switch to the kernel page table
- Doesn’t switch to a stack in the kernel
- Doesn’t save any registers other than the pc
User Space Traps
- In RISC-V, the hardware doesn’t switch page tables on a forced trap. This means that the trap handler address must have a valid mapping in the user page table and in the kernel page table
- each process automatically gets assigned a trampoline page, which is located at the top of the virtual address space above any user code
- Cruicially, it is located at the same address in user and kernel space, which makes the transition between the two easy
- The
csrwinstruction copies a register over tosscratch - the TRAPFRAME is saved just below the TRAMPOLINE virtual address
- Once all of the registers are copied, you switch to the kernel page table, then figures out what trap occurred, then dispatches the correct subroutine
- Once the interrupt routine finishes, the RISC-V reloads the old program counter, then switches to the original user page table
Syscalls
- the arguments for exec are placed in a0 and a1, and places the system call number in a7. This system call number indexes into a syscall array, which is an array of function pointers
- After the associated syscall returns, the return value is recorded in p->trapframe->a0
- C calling convention on RISC-V places return values in a0
- Conventionally, negative numbers are errors, positive number are success
Kernel Space Traps
- Upon entering the kernel, all 32 registers are pushed to the stack for later restoration
- Importantly, they are saved on the interrupted kernel thread. So if the trap causes a switch to a different thread, then these interrupted threads will be preserved
- If an interrupt was due to a timer interrupt, and a process’s kernel thread is running, then the current thread yields to allow other threads to run
- Once a trap is done, it returns to the original code
- There in theory can be a race condition when the ‘stvec’ register is still set ot uservec instead of kernelvec. If an interrupt occurred in the interim, that would be bad
- RISC-V disables interrupts when it starts to take a trap, and they don’t get enabled until after it sets stvec
Page Fault Exceptions
- For xv86, if an exception occurs in user space, the kernel kills the faulting process. If an exception happens in the kernel, the kernel panics. Real kernels can do more interesting things
- For instance, copy-on-write (COW) fork. The basic idea is that when you create a fork, you need to copy over the memory space of the parent to the child. Xv6 allocate a separate chunk of physical memory for the child. it would be nice if you could use the same physical memory, but a naive implementation would cause the two processes to step over each other
- the CPU can raise a page-fault exception if a virtual address has no mapping in the page table, or PTE_V is cleared, or a process doesn’t have the correct permissions
- Initially, parent and child shares all physical pages, but both are read-only. If a page-fault from an attempted write occurred, then a new page of physical memory is allocated for that process, but now with write enabled. Subsequent writes are unimpeded
- Many use cases of fork() doesn’t allocate new memory, so this save a bunch of page allocations
- Lazy allocation is another use case. If an application demands memory, the kernel keeps track of the increase in size, but doesn’t allocate any physical memory until a page fault occurs
- If an application asks for more memory than it needs, you save on allocating all those pages
- Even if the application massively grows the address space, you can spread out the cost of allocating that space over time
- This does incur the overhead of more paging requests, but you can allocate a small number of pages on page fault
- There is demand paging. Naively (like xv6 does), one loads in all of the application text and data into memory before starting the application. You can instead create a user page table with all PTEs marked invalid. Once the program starts and encounters a page for the first time, the kernel allocates that page
- Programs might need more memory than there is in RAM. the kernel splits the data between RAM and disk, and marks all the disk pages as invalid. If a disk page gets hit, then a new page is allocated in RAM, the page from the disk is copied over, and the PTE is pointed to RAM (this process is called ‘paging in’. ‘paging out’ goes the other way)
- If there is no free physical RAM, then the kernel must free a physical page (or evict it) from RAM to the disk, and mark the page as invalid again. This is expensive
- eviction is infrequent if an application only uses a subset of their memory pages which can all fit in RAM
- Most computers have little to no free memory (think multiplexing user on a cloud computer). When free physical memory is scarce, allocation is expensive
Interrupts ad Device Drivers
- A “driver” refers to code in an operating system that manages a particular device. This means setting the device up, handling interrupts, and mediate processes waiting for I/O from the device
- Importantly this need to be done in an thread safe concurrent fashion
- Typically, you can split a driver into two halves
- The top half runs in a process’s kernel thread. This is called via system calls such as read and write that want to perform device I/O
- The bottom half executes at interrupt time. On interrupt, the bottom figures out what was done, wakes up a waiting process if needed, and then tells the hardware to start work on any queued operation
Console Input
- The console driver takes inputs from the UART serial-port hardware and stores it in a line buffer. User processes then use the read syscall to fetch these lines from the console
- The UART appears to software via a set of memory-mapped control registers. That is, certain addresses map to the hardware instead of RAM
Console Output
- The device driver maintains some output buffer so that writing processes don’t need to wait for the UART to finish sending
- You need to wait if the buffer is full though
- This is a general pattern: You decouple the device activity from the process activity via buffering and interrupts
- The console driver can process input even when no process is waiting to read it
- Similarly, processes can send output without having to wait for the device
- This decoupling technique is called I/O concurrency. It’s useful for slow devices (like UART) or if you need to do immediate action
Timer Interrupts
- Xv6 needs timer interrupts to maintain the current time, and switch amoung compute-bound processes
- These are just roll-over counters with a fixed increment frequency and well defined thresholds for rollover (stimecmp in Xv6)
- Timer interrupts only increment time for one CPU (prevents time from passing faster if therer are multiple CPUs)
- The kernel code may be moved from one CPU to another without warning
Locking
- Most kernels allow the execution of multiple activities
- Multiple CPUs can execute independently
- Multiple CPUs share physical RAM, which allows data structures to be shared between them
- A CPU, even on a single processor system, can switch between multiple threads of execution
- A device interrupt handler can interrupt at any time
- You need to manage this parallelism in order to ensure correctness of program execution (concurrency control techniques)
- Locks provide mutual exclusion, ensuring that only one CPU at a time can hold the lock
- Upside: Easy to understand
- Downside: Serializes concurrent operations
Races
- Imagine that you have your bog standard linked list
struct element {
int data;
struct element *next;
};
struct element *list = 0;
void
push(int data)
{
struct element *l;
l = malloc(sizeof *l);
l->data = data;
l->next = list;
list = l;
}
- What happens if two CPUs execute push on the same linked list?
- Only the one that occurs latter in time will be successfully realized. The first one will get lost. This is an example of a race
- Races occur when simultaneous memory access occurs with at least one being a write
- The outcome of races can depend on
- The machine code generated by the compiler
- The timing of the two CPUs involved
- How the two CPU memory operations are ordered by the memory system
- Locks are one way of avoiding races. Locks ensure mutual exclusion, so that only one CPU can execute the offending lines of code at a time
- These sections are often called critical sections
- Locks protect data by maintaining invariants on the data
- In the critical sections, these invariants might be violated, but at the end, the invariants should hold again
- Look at linked lists: The invariant is that the head of the list points to the first element, and the next field points to the next element
- push temporarily violates this invariant when it updates the pointers. Locks ensure that is section is run by only one CPU
- Locks decrease performance by serializing concurrent code
- If multiple processes need a lock at the same time, then they are in contention with each other
- A big part of kernel design is to avoid locks when possible via clever data structures and algorithms
- Locks also need to be placed correctly. If they are two wide, they can be serializing code which doesn’t need to be
- Linked lists again: if you locked the entirety of push, then even malloc would be serialized when it doesn’t need to be
Spinlocks
- One implementation of locks is a spinlock. You have one bit of data which represents if a lock has been acquired or not. Naively, one might implement this like
void
acquire(struct spinlock *lk) // does not work!
{
for(;;) {
if(lk->locked == 0) {
lk->locked = 1;
break;
}
}
}
- The problem occurs at the if statement. If two CPUs both reach line 25, they both might see that lk->locked is 0, which means both of them acquire the lock. This violates mutual exclusion
- To get around this, most multi-core CPUs have some sort of atomic read and swap instruction which does the following in an uninterruptible way (using
ampswap r, ain RISC-V as an example):- reads the value at memory address a
- writes the contents of register r to address a
- puts the read value into r
- in Xv6, acquiring and releasing a lock basically boils down to using this instruction
- To acquire a lock, a CPU continually spams the ampswap instruction by writing a 1 to lk->locked
- If you get a 1 in the return value, then you know that some other CPU has the lock
- If you get a 0, then this means that no other CPU was holding the lock previously. Hence, the current CPU now has exclusive ownership of the lock and can move on with life
- Release works in a similar way, but spams 0 instead
Using Locks
- It can be difficult to figure out what data and invariants each lock should protect
- Some principle to help guide you:
- Any time a variable can be written by one CPU at the same time that another CPU can read or write it, a lock should be used to keep the two operations from overlapping
- If an invariant involves multiple memory locations, typically all of these locations need to be protected by a single lock to ensure the invariance is maintained
- The above are rules for when locks are necessary, but they say nothing about when they are unnecessary
- You can divide locking into “coarse-locking” and “fine-locking” to handle different speed requirements
- For instance, in Xv6, there is a single free list with a single global lock (coarse grain)
- For the file system, each file has it’s own lock, so that processes manipulating different files don’t need to wait for each
- You can divide locking into “coarse-locking” and “fine-locking” to handle different speed requirements
Deadlocks
- Locks need to be acquired and released in the same order, otherwise, you get deadlocks
- For instance, if one CPU acquires B then A, and the other acquires A then B, then both CPUs will be waiting for the other to finish and will stall
- For Xv6, there are well defined lock ordering which must be maintained
- daf
- In general, it’s difficult to maintain global deadlocking avoiding order
- For instance, module M1 might call module M2, but the lock order requires the lock in M2 to be acquired before M1
- This sets constraints on how fine grained that you can set your locks
- One way that you might be able to avoid deadlocks is with re-entrant locks (or recursive locks)
- This means that if a process attempts to acquire a lock it already has, then the kernel just allows it instead of panicking
struct spinlock lock;
int data = 0; // protected by lock
f() {
acquire(&lock);
if(data == 0){
call_once();
h();
data = 1;
}
release(&lock);
}
g() {
aquire(&lock);
if(data == 0){
call_once();
data = 1;
}
release(&lock);
}
h() {
...
}
- Take a look at the above code, you would expect that call_once() would be called once, either by f or by g, but not by both
- If re-entrant locks are allowed and h happens to call g, call_once will be called twice
- Without recursive locks, you would get a deadlock. Either bug is bad, but a deadlock is easier to track down since the kernel panics on deadlock, but silently fails with reentrant locks
- If you wanted to use reentrant locks, then you would need to keep track of the depth of the lock
- You can get deadlocks with interrupts as well
- For instance, suppose that a CPU acquires a lock for sys_sleep, and the CPU gets a timer interrupt. The interrupt will try to get the lock, won’t be able to get it, and then will wait for it to be released. sys_sleep won’t every release until the timer interrupt is handled
- To avoid this, if a spinlock is used by an interrupt handler, a CPU must naver hold the lock while interrupts are enabled
- Xv6 is more conservative: if a CPU acquires any lock, then interrupts are disabled on that CPU
- You can also uncover deadlocks when the compiler does out of order execution
- Mentally, you can think of assembly code are running in the order that the code is written is
- This is not the case: compiler might reorder your code, omit extraneous memory stores and loads, run independent sections of code in parallel etc.
- That last one isn’t perfect. You can get code that works sequentially, but fails miserably when done out of order
- You can tell a compiler not to re-order via memory barriers (__sync_syncrhonize() in C library)
Spinlocks
- Sometimes, a lock needs to be held for a long time
- Say in the file system, a file is held for tens of milliseconds while read and write operations happen
- Spinlocks are not good for this situation since a lot of CPU time is wasted spinning the lock
- Another drawback is that a process cannot yield the CPU while retaining the spick lock
- ie. Another process wants to use the CPU while your waiting for the slow disk
- if you yield with a spinlock, then you run into the possibility that another thread of the CPU tries to acquire the spinlock. You then have both threads waiting for each other to finish (deadlock!)
- The solution to this is sleep-locks
- This consists of a locked field which is protected by a spinlock, and
acquiresleep’s call which does an atomicsleepon the CPU, yielding as needed - Since sleep locks keep interrupts enabled, the cannot be used in interrupt handlers
- This consists of a locked field which is protected by a spinlock, and
Scheduling
- Operating systems typically run more processes than the computer has CPUs, so you need some way to time-share the CPUs amongst the processes
- Ideally, this sharing should be transparent to the user
- A common way to do this is to give the illusion that each process has it’s own CPU by multiplexing processes (ie. the work of a process gets shared between CPUs)
- There are a bunch of challenges that you need to handle to get this working
- First, you need to be able to save and restore CPU registers (this needs to be done in assembly)
- How do you force switches in a way that is transparent to user processes?
- Xv6 uses the standard technique in which hardware timer interrupts drive context switches
- all CPUs switch amoung the same set of processes, so you need a locking plan to avoid races
- A process’s memory and other resources must be freed when the process exits, but it can’t do all of this itself for various reasons
- One of these is that it can’t free ints own kernel stack while still using it
- Each CPU must remember which process it is executing so that syscalls affect the correct process kernel
- Finally, sleep and wakeup allow a process to give up the CPU and wait to be woken up by another process or interrupt
Context Switching
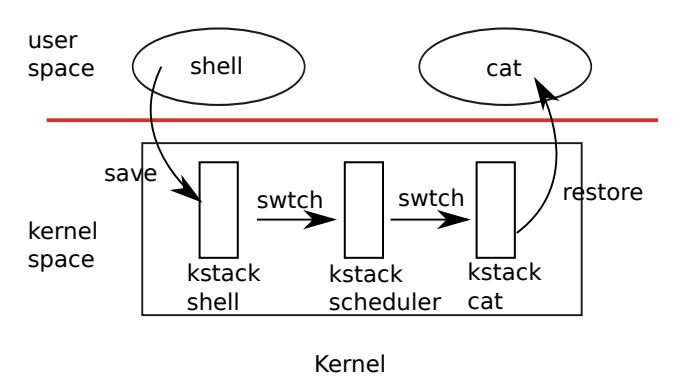
- The above shows how you switch from one user process to another
- a trap from user space to the old process’s kernel thread
- a context switch to the current CPU’s scheduler thread
- a context switch to a new process’s kernel thread
- a trap return to the new user-level process
- Xv6 has dedicated threads which execute the scheduler because it’s not safe for the scheduler to execute on any process’s kernel stack
- Another CPU might wake the process up and run it, and it would be bad to have the same stack on two different CPUs
- Hence, each CPU has it’s own scheduler thread to cope with situations in which more than one CPU is running a process
- Upon a context switch, the CPU scheduler thread will save the old process’s registers, stack and program counter, and then load the new process’s registers, stack and program counter
- The function
swtchdoes this save and restore. It only focuses on saving and restoring as set of 32 RISC-V registers, collectively called “contexts” swtchonly saves the callee registers. It does not save the program counter; it save the ra register (ie. the return address from which swtch was called)- After that, swtch restores registers from the new context, which holds the register value of a previous swtch call. Upon return, the instrutions point to the restored RA (ie. the instruction which called swtch). It also returns on the new thread’s stack
- The function
Scheduler
- Basic ideas is that if a process wants to give up the CPU, it must
- acquire its own process lock
- release any other locks it is holding
- update its own process state
- Disables interrupts
- then call the scheduler
- Each CPU runs a scheduler in it’s own dedicated thread
- The CPU checks that the above sequence was run, then context switches to the scheduler thread
- The scheduler then dispatches to any waiting processes
- The CPU checks that the above sequence was run, then context switches to the scheduler thread
- NOTE: the process lock is held across context switches
- This must be done since context switching does not preserve invariants. The lock can only be released if
- the scheduler clears the cpu’s process
- the new process’s kernel is completely up and running
- This must be done since context switching does not preserve invariants. The lock can only be released if
- The scheduler in Xv6 is very simple
- It loops through the process table and looks for a process that is RUNNABLE, sets that process to RUNNING, then context switches and waits for it to yields. It then continues on
Sleep and Wakeup
- What if you need two threads to communicate with each other? Xv6 uses a mechanism called sleep and wakeup
- Sleep allows a kernel thread to wait for a specific event
- A thread can call wakeup to indicate that threads waiting on a specific event should resume
Semaphores
- As an example of the utility of Sleep and Wakeup, let’s try and implement a higher-level syncrhonization mechanism called a semaphore.
- Semaphores maintain a spinlock and a reference count
- “Producers” can increment this count when ready
- “Consumers” busy wait for this count to be non-zeroo, then decrement the counter and return
- Semaphores maintain a spinlock and a reference count
- A naive implementation might look like
100 struct semaphore {
101 struct spinlock lock;
102 int count;
103 };
104
105 void
106 V(struct semaphore *s)
107 {
108 acquire(&s->lock);
109 s->count += 1;
110 release(&s->lock);
111 }
112
113 void
114 P(struct semaphore *s)
115 {
116 while(s->count == 0)
117 ;
118 acquire(&s->lock);
119 s->count -= 1;
120 release(&s->lock);
121 }
- This implementation is expensive, since the consumer is busy waiting for potentially long periods of time
- To avoid the busy wait would require the consumer to yield the CPU, and only resume after function V increments the counter
- Suppose that there exists some functions sleep(chan) and wakeup(chan)
- sleep(chan) puts the calling process to sleep and releases the CPU for other work
- wakeup(chan) wakes all processes that are in sleep calls with the same channel number. If no processes are waiting on chan, wakeup does nothing
- The above allows us to change the semaphore implementation as follows
200 void
201 V(struct semaphore *s)
202 {
203 acquire(&s->lock);
204 s->count += 1;
205 wakeup(s);
206 release(&s->lock);
207 }
208
209 void
210 P(struct semaphore *s)
211 {
212 while(s->count == 0)
213 sleep(s);
214 acquire(&s->lock);
215 s->count -= 1;
216 release(&s->lock);
217 }
- The consumer is no longer busy waiting (it gives up the CPU instead)
Lost Wake-Up Problem
- The above sleep and wakeup implementation runs into the “Lost Wake-Up” Problem
- Suppose that P finds that s->count ==0 on line 212. While P is between lines 212 and 213, V runs on another CPU, which changes s->count to be nonzero and calls wakeup, which finds no processes and does nothing. P executes lines 213, but missed the previous wake-up, so it continuously sleeps.
- You need to wait for V to send another wakeup, which might never happen
- This happens because the invariant that P sleeps only when s->count==0 is violated by V running at just the wrong moment
- Naively fixing this by moving the acquire call creates a deadlock
- THe actual fix is to change the interfact of sleep to be sleep(chan, cond_lock), where cond_lock is the semaphore’s spinlock. This allows the lock to be released only after the process has be properly put to sleep
- This forces a concurrent V to wait until P as finished sleeping
- Hence, the proper implementation is
400 void
401 V(struct semaphore *s)
402 {
403 acquire(&s->lock);
404 s->count += 1;
405 wakeup(s);
406 release(&s->lock);
407 }
408
409 void
410 P(struct semaphore *s)
411 {
412 acquire(&s->lock);
413 while(s->count == 0)
414 sleep(s, &s->lock);
415 s->count -= 1;
416 release(&s->lock);
417 }
Pipes
- A pipe struct consists of
- a spinlock
- a data buffer
- nread and nwrite keep track of the number of bytes read/written
- The buffer is a circular buffer (ie. the next byte after $buf[PIPESIZE-1]$ is $buf[0]$). nread and nwrite do not wrap around
- This convention allows ups to distinguish between a full buffer (nwrite=nread+PIPESIZE) from an empty buffer(nwrite==nread)
- To index the buffer, you need to use an index of nread % PIPESIZE instead of nread
- The pipe works by busy-waiting for the lock to free
- If writing, the pipe writes to the buffer until it’s out of data, or the buffer is full.
- If the buffer gets full, then wakeup is called to alert any sleeping readers that there is data to be read
- The write pipe then sleeps and waits for a wakeup call indicating that the pipe has space
- sleep releases the pipe’s lock during this process
- If reading, then after acquiring the lock, the pipe reads from the buffer until the buffer is empty or the desired bytes have been recovered
- If the buffer is empty, then you read all the available bytes, then send a wakeup to all sleeping write pipes
- If writing, the pipe writes to the buffer until it’s out of data, or the buffer is full.
Process Locks
- p->lock must be held while reading or writing any of the following proc fields
- p-> state, p->chan, p->killed p->xstate, x->pid
- This is because these fields can be used by other processes
- On a higher level, p->lock also
- prevents race conditions (along with p->state) when allocating new processes
- Conceals a process from view while it is being created or destroyed
- Prevent a parent’s wait from collecting a process that has set its state to ZOMBIE but has not yet yielded the CPU
- It prevents another CPU’s scheduler from deciding to run a yielding process after it sets its state to RUNNABLE but before it finishes swtch
- Ensures only one CPU’s scheduler decides to run a RUNNABLE process
- prevents a timer interrupt from causing a process to yield while it is in swtch
- Prevents wakeup from overlooking a process that is calling sleep but hasn’t yielded the CPU yet
- Prevent the victim process of kill from exiting
- makes kill check and write p->state in an atomic fashion
Real World Scheduling
- Xv6 uses round-robin shedueling, where each process is run in turn. Real schedulers might implement some priority scheme so that some processes are given preferential treatment. This is a hard thing to do (things like priority inversion and convoys can happen)
- sleep and wakeup is a simple synchronization method, but it’s not the only one: for example, the Linux kernel uses an explicit process queue
- Linear scans of the processes during wakeup is inefficient. There are a variety of data structures which could be more efficient.
- In the context of threading libraries, this structure is referred to as a condition variable
- sleep is mapped onto wait
- wakeup is mapped onto signal
- In the context of threading libraries, this structure is referred to as a condition variable
- wakeup currently wakes up all sleeping processes on a particular channel. This causes all the processes to wake up and rush to grab the lock
- This sort of behavior is called “a thundering herd”
- A more sane way might be to have a way to wakeup only one process on a channel, or broadcast a wake up to all sleeping processes on a channel
File System
- A file system’s purpose is to organize and store data; it allows one to share data amoung users and applications, as well as persistence so that data is still available after a reboot
- There are lots of challenges a file system must handle
- You need on-disk data structures to represent the tree of named directories, the identities of the blocks that hold a file’s content, and to record the free areas of the disk
- Support crash recovery: If a crash occurs, the file system should still work/ be self-consistent
- Different processes must be able to operate on the file system at the same time, so the file system must manage invariants
- The file system needs an in-memory cache of hot blocks, since disk access is orders of magnitude sower than accessing memory
- Xv6 uses a 7 layer file system. From bottom up
- the first layer is the disk
- the buffer cache layer caches disk blocks and synchronizes access to them, ensuring that only one kernel process at a time can modify the data stored in any particular block
- Logging layer allows higher layer to wrap updates as atomic transactions. This ensures that the blocks are updated atomically in the face of crashes
- The inode layer provides individual files
- Each inode as a unique i-number and some blocks which hold the file data
- The directory layer implements each directory as a special kind of inode whose content is a sequence of directory entries, which each contains a file’s name and i-number
- The pathname layer provides hierarchical path names and resolves then with recursive lookup
- The file description layer creates a top-level file system interface for user-level programs
- Disk hardware traditionally presents data on the disk in 512-bit wide blocks called sectors. These sectors are sequentially layed out
- For instance, sector 0 is the first 512 bits, sector 1 is the next 512 bits etc.
- Xv6 holds recently read sectors in memory
- This data sometimes is out of sync with the disk (perhaps it hasn’t read from the disk, or maybe the cached data has been updated by the software, but not the hardware)
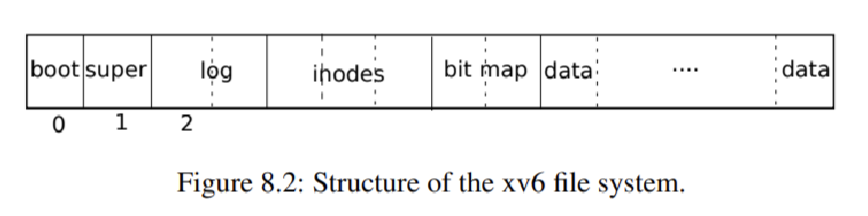
- Xv6 splits the file system up into several blocks:
- Block 0 is the boot sector. The filesystem doesn’t touch this
- Block 1 is the superblock. It contains meta data bout the file system (file system size in blocks, the number of data blocks, the number of inodes, and the number of blocks in the log)
- Block 2 holds the rest of the file system
Buffer Cache Layer
- Has two jobs
- Synchronize access to disk blocks to ensure that only one copy of a block is in memory and that only one kernel thread at a time uses that copy
- Cache popular blocks so that they don’t need to be re-read from the slow disk
- The interface of Xv6 uses
- bread obtains a buf struct which contains a copy of the block which can be read or modified in memory
- bwrite pushes this modified buffer to the appropriate block on the disk
- brelse frees the buffer once it’s done
- The buffer cache uses a doubly linked list of buffers
- This gets initialized with NBUF empty buf structs
- Each buffer has a valid field, which states wheather the buffer contains a copy of the block, and a disk field, which indicates that the buffer content has been handed to the disk
- If you reach the end of the list and you ask for a block that is not in the cache, the buffer cache boots out the least recently used buffer for the new block
- bget scans the buffer list for a buffer with the given device and sector numbers. If there are none in the cache, then the least recently used block in the cache is forcibly cleared, made invalid so that bread is forced to go to disk, then presented as the return from bread
- brelse releases the sleep lock on a buffer, then moves that buffer to the front of the linked list. This orders the list from front to back by how recently the buffer was released
Logging Layer
- Suppose that you only perform a subset of writes before the computer crashes
- The crash may leave an allocated but unreference content block
- The crash might also leave an inode with a reference to a content block
- If xv6 supports multiple users, then the latter would allow the old file’s owner to read and write block in the new file, owned by a different user
- Xv6 performs logging by keeping a seperate log which describes all the write a syscall wants to perform. Once all of them are queued up, the syscall writes a commit record to the disk indicating that the log contains a complete operation. The syscall then copies the writes over to the disk. After the writes complete, the log on the disk gets erased
- Imagine a crash happens
- If a log is marked as containing a complete operation, then the recovery code copies the writes to where they belong
- If a log is not marked as complete, the recovery code ignores the log
- In either case, the log gets erased by the recovery code
- Let’s think about why this works:
- If the crash occurs before the operation commits, then the log in the disk will not be marked as complete. The recovery code will ignore it and the state of the disk will be as though the operation didn’t happen
- If the crash occurs after the operation commits, then recovery will replay all of the operation’s writes
- It might even repeat some that the operation has started prior to the crash
- The above makes disk writing atomic: either all the writes appear on the disk, or none of them appear
- On Xv6, the log resides in the superblock
- It contains a header block, followed by a sequence of updated block copies
- The header contains an array of sector numbers (one for each logged block) and the count of log blocks
- The count is either zero (indicating no blocks) or non-zero (indicatin the log contains a completed transaction with the indicated number of logged blocks)
- Xv6 write the header block when a transaction commits. The counter gets set to 0 after copying the logged blocks to the file system
- So a crash midway through a transation will result in a count of zero
- A crash after a commit will have a non-zero count
- The log can accumulate logs across many syscalls. To avoid splitting a syscall across transactions, the logging system only commits when no file-system syscalls are happening
- This batching of transactions is known as group commit
- The log has a fixed amount of disk space. If a syscall asks for too many blocks, then you need to split these blocks up so that everything fits (for instance, write() could asks for many blocks)
Block Allocator
- We have a free pool of disk blocks which need to be allocated
- Xv6 block allocator uses a bitmap on disk. A zero bit in the mask indicates the block is free. Otherwise, it is in use
- Mkfs sets the bits corresponding to the boot sector, superblock, log blocks, inode blocks and bitmask blocks
- The block allocate provides two functions
- balloc allocates a new disk block. This loops over all possible blocks (from 0 to sb.size), looking for a free block. Once found, the bitmap is updated and the block is returned
- There is an optimization where the loop is split into two parts. The outer loop reads seach block of bitmap bits. The inner loop checks all Bits-Per-Block (BPB) in a single bitmap block
- A race might occur if two processes try to allocate a block at the same time, but the buffer cache prevents this by only letting one process use any one bitmap block at a time
- bfree finds the right bitmap block and clears the right bit
- balloc allocates a new disk block. This loops over all possible blocks (from 0 to sb.size), looking for a free block. Once found, the bitmap is updated and the block is returned
Inode Layer
- Inode has two meanings
- The on-disk data structure containing a file’s size and list of data block numbers
- An in-memory inode, which contains a copy of the on-disk inode as well as extra information needed within the kernel
- The on-disk inodes are in a contiguous area called the inode blocks. Each inode is the same size. Each inode has a i-number which states where in this contiguous array that it lives at
- struct dinode contains
- a type field which distinguishes between files, directories, and special files (ie. devices). A type of zero indicates that the inode is free
- nlink field counts the number of directory entries that refer to this inode. Needed to know when the on-disk inode and its data blocks should be freed
- size field counting the number of bytes of content in the file
- addrs array records the block number of the disk blocks holding the file’s content
- The active inodes in memory are kept in an itable
- a struct inode is only stored if there is a C pointer referring to that inode
- the refs field in inode keeps track of these C pointers. Once the number of pointers hits 0, the kernel discards the inode from memory
- a struct inode is only stored if there is a C pointer referring to that inode
- There are 4 locking mechanisms in the inode code
- itable.lock protects the invariant that an inode is present in the inode table at most once, as well as the invariant that an in-memory inode’s ref field counts the number of in-memory pointers to the inode
- Each in-memory inode has a lock field containing a sleep-lock, which ensure exclusive access to the inode’s fields
- a non-zero ref field forces the system to maintain that inode in the table
- nlink counts the number of directory entries that refer to a file. Xv6 won’t free an inode if the link count is greater than 0
- iget() returns an inode pointer that is gaurenteed to be valid until the matching iput() is called
- In words, iget() provides non-exclusive access to the the inode, which some processes depend on (think knowing if a file is open or not)
- If you want the inode structure to be populated with the most recent update of the inode, then you need to call ilock() and iunlock() to get exclusive ownership, and then read from the disk
- This seperation helps avoid deadlock in some scenarios (say directory lookup)
Directory Layer
- Directories are implemented internally like a file (ie. inodes)
- Directories have a linked list of names and inodes numbers. Directories with inode number zero are free
- the function dirlookup() searches a directory for an entry with a given name. If it finds one, it returns a pointer to the correesponding inode and sets *poff to the byte offset of the entry within the directory
- The function dirlink() write a new directory entry into the specified directory by looping through the directory entries; If an unallocated entry is found, the inode is created at that offset
Path Layer
- Path name lookup involves sucessive calls to dirlookup. The starting point is either the root directory or the current directory
- After locking the current directory pointer, you scan through the entries, set the current directory to the found directory, and then interate on that new directory
- There are some concurrency issues:
- One kernel thread is looking up a pathname while another kernel thread may be changing the directory tree by unlinking a directory. A potential risk is that a lookup may be searching a directory that has been deleted by another thread
- Locking a directory when doing path lookup and reference counting inodes are some deadlock prevention mechanisms
- One kernel thread is looking up a pathname while another kernel thread may be changing the directory tree by unlinking a directory. A potential risk is that a lookup may be searching a directory that has been deleted by another thread
File Descriptor Layer
- Everything is a file in UNIX. Everything! This layer helps acheive this uniformity
- Each process gets its own table of open files (file descriptors)
- struct file is a wrapper around inode or pipe, plus an I/O offset
- each open() cll create a new open file
- Multiple processes can have the same open file, but different I/O offsets
- A single file can appear multiple times in one process’s file table; it can also appear across multiple processes
- This could happen with dup or fork
- All open files are kept in a global file table (ftable)
- Filealloc scans the file table for an unreferenced file and returns a new reference
- Filedup increments the reference count
- fileclose decrements this counter. When the counter hits 0, the underlying pipe or inode is released